
阿里巴巴新出了千问3的模型,我想着用我的老电脑的cpu试一下,过程中遇到了一些问题,这里记录下。
1. 目标
在一台 16 GB 内存的 MacBook 上,用纯 CPU 方式运行 Qwen3-4B-Instruct-2507 模型,完成中文对话式推理。
- 不依赖 GPU:全程在系统内存和多核 CPU 上执行。
- 零冲突复现:提供一套简单、可复制的流程,避免 Python 依赖版本地狱。
我的电脑配置如图:

2. 遇到的坑
Metal 后端初始化失败
llama-cpp-python默认会加载 Metal 着色器库,报ggml_metal_init: metal library is nil ggml_metal_init: failed to allocate context导致无法运行。
模型架构不识别 PyPI 上的旧版
llama-cpp-python不支持最新的qwen3架构,加载 GGUF/模型时报unknown model architecture: 'qwen3'Python 依赖冲突
safetensors ↔ PyTorch:
safetensors内部硬编码了torch.uint16/uint32/uint64,但 CPU-only PyTorch 只定义了torch.uint8,导入立刻抛AttributeError: module 'torch' has no attribute 'uintXX'NumPy 版本不兼容:部分 C 扩展编译依赖于 NumPy 1.x,升级到 2.x 会引发崩溃。
源码编译痛点
- 克隆
llama-cpp-python时子模块vendor/llama.cpp未带上,CMake 找不到底层库。 - pip 直链 GitHub 多次因超时失败。
- 克隆
3. 解决思路与最终方案
3.1 直接用 llama.cpp CLI(推荐)
编译最新 llama.cpp
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp cmake -S . -B build cmake --build build --config Release --parallel $(sysctl -n hw.ncpu)转换 Hugging Face safetensors → 单文件 GGUF
python convert_hf_to_gguf.py \ --model ~/.cache/modelscope/hub/models/Qwen/Qwen3-4B-Instruct-2507 \ --outfile ~/models/Qwen3-4B-Instruct-2507.gguf纯 CPU 推理
cd build/bin ./llama-cli \ --model ~/models/Qwen3-4B-Instruct-2507.gguf \ --prompt "请写一段古风小诗,题目是《秋思》" \ --threads 4 \ --ctx-size 2048 \ --n-predict 128 \ --temp 0.7 \ --top-k 40
这样完全绕开 Python 库冲突,支持 qwen3 架构,性能稳定。
3.2 Python 方案(附加补丁)
如果仍想用 transformers + PyTorch,可在项目根目录下新建 sitecustomize.py,在 Python 启动时自动打补丁,避免 safetensors 报错:
# sitecustomize.py
try:
import torch
for name, alias in [
("uint16", torch.int16),
("uint32", torch.int32),
("uint64", torch.int64),
]:
if not hasattr(torch, name):
setattr(torch, name, alias)
except ImportError:
pass为什么会遇到这些问题?
- 模型太新:Qwen3 属于最前沿架构,旧版工具链没法识别,必须用最新代码或
trust_remote_code。 - 半精度格式差异:配置文件中
"torch_dtype": "bfloat16"是 16 位格式;CPU 环境下常回退到float32。 - safetensors ↔ PyTorch dtype 映射:
safetensors硬编码了多种无符号类型,但 CPU-only PyTorch 未定义,需补丁或合适版本。
小结
- 最稳妥:用最新 llama.cpp CLI,零 Python 冲突、零依赖。
- 可选:Python 补丁配合环境导出,实现 Transformers 方案。
- 环境导出:
conda env export+pip freeze,让读者一键复现。
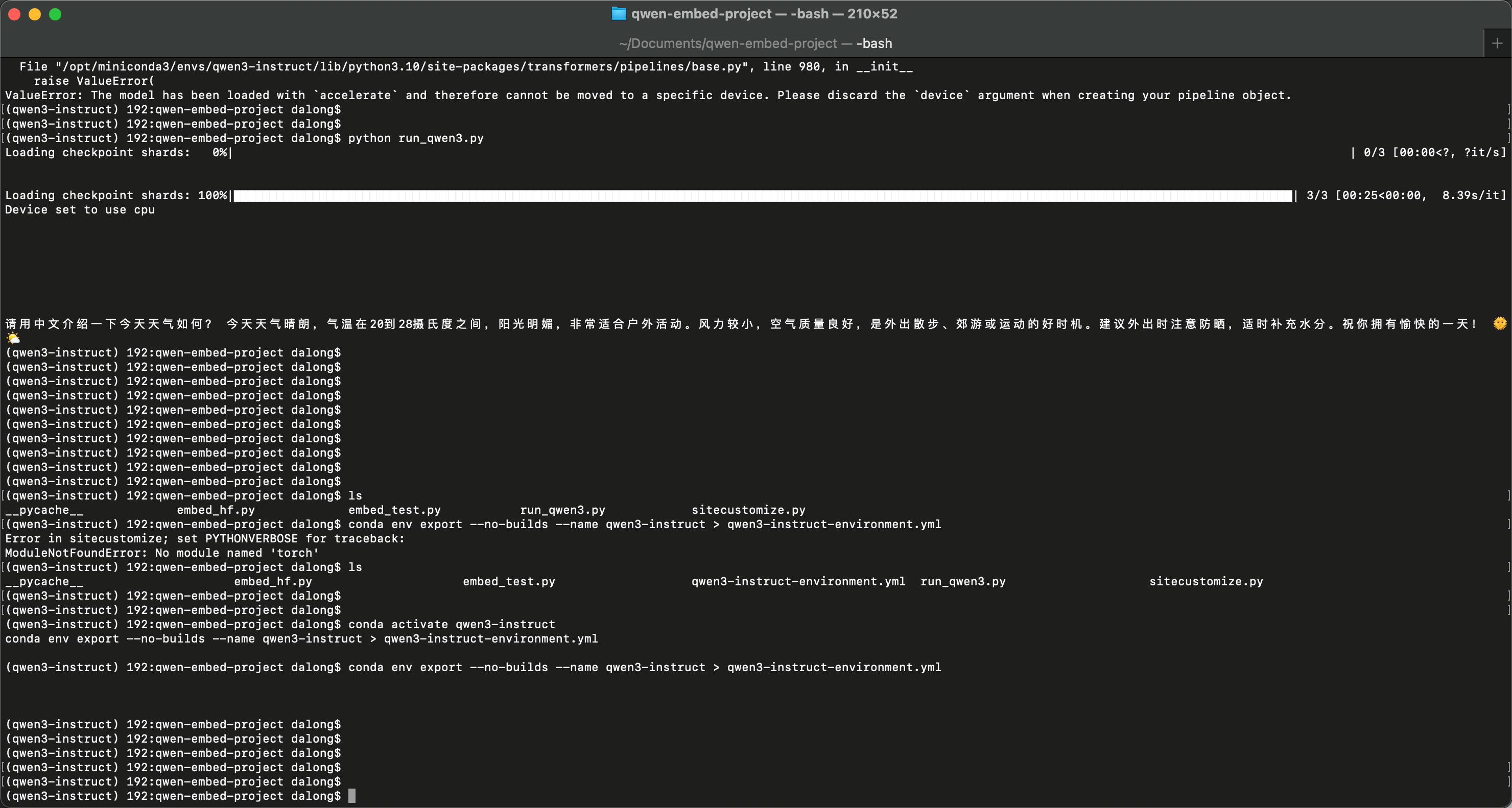
成功效果图,推理巨慢,半小时才出结果:
建议的配置与流程
为什么这么慢呢?
在这台 2018 年款 MacBook Pro(16 GB DDR4-2400,6-核 Intel i7,Radeon Pro 555X + Intel UHD 630)上,用纯 CPU(PyTorch/transformers)来跑一个 4 B 参数级别的模型,实际体验大致是这样的:
FP32/FP16 原始模型(无量化、无特征加速)
启动加载:模型权重十几 GB,几乎会把 16 GB RAM 吃满,常常卡在 “加载” 阶段并触发很长的磁盘→内存交换,可能需要 数分钟 甚至更久,或直接因 OOM 报错。
推理速度:即便加载成功,也通常在 0.2–0.5 token/s 左右(5–10 秒/token)。
- 生成 50 token = 1–8 分钟
- 生成 200 token = 20–80 分钟
量化+高效推理(推荐)
使用 llama.cpp(或类似“ggml”库)把模型量化到 4 位或 8 位,开启 AVX/AVX2 优化:
q4_0(4 bit):可以跑到 10–20 token/s。
- 生成 100 token = 5–10 秒
q8_0(8 bit):可以跑到 5–10 token/s。
- 生成 100 token = 10–20 秒
优势:极大降低内存占用(2–4 GB),避免 OOM,且秒级响应。
为何不能利用你的 Radeon Pro 555X 或 UHD 630 加速?
- Apple MPS 后端仅支持 Apple Silicon(M1/M2 系列)。Intel + Radeon GPU 在 PyTorch/transformers 上没有通用加速方案,只能靠 CPU。
准备量化模型
# 例如用 llama.cpp 工具链把 HF checkpoint 转成 q4_0 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp ./convert.py path/to/model.bin --outfile model-q4_0.bin --quantize q4_0安装并运行 llama.cpp
make ./main -m model-q4_0.bin -p "你好,模型!" -t 6-t 6指定 6 线程,你也可以根据htop监控,尝试4–8线程的平衡点。
体验速度
- 量化后常可以看到 10–20 token/s,生成一个短答(50 字)只要 不到 1 秒。
小结
- 纯 CPU 非量化:几秒到几分钟/token,根本达不到交互速度。
- 量化 + llama.cpp:秒级响应,且稳定跑在你这台 16 GB MacBook Pro 上。
如果你想在本地玩转 4 B、7 B 这样的模型,强烈推荐走量化+ llama.cpp(或 ONNX Runtime+OpenVINO、CTranslate2)这条路。这样就不用再“等半天”了。
导出文件:
# qwen3-instruct-environment.yml
name: qwen3-instruct
channels:
- pytorch
- defaults
dependencies:
- aom=3.6.0
- blas=1.0
- brotlicffi=1.0.9.2
- bzip2=1.0.8
- ca-certificates=2025.2.25
- cairo=1.16.0
- certifi=2025.7.14
- cffi=1.17.1
- charset-normalizer=3.3.2
- cpuonly=2.0
- dav1d=1.2.1
- expat=2.7.1
- filelock=3.17.0
- fontconfig=2.14.1
- freetype=2.13.3
- fribidi=1.0.10
- gettext=0.21.0
- gmp=6.3.0
- gmpy2=2.2.1
- graphite2=1.3.14
- harfbuzz=10.2.0
- icu=73.1
- idna=3.7
- intel-openmp=2023.1.0
- jinja2=3.1.6
- jpeg=9e
- lcms2=2.16
- lerc=4.0.0
- libavif=1.1.1
- libcxx=17.0.6
- libdeflate=1.22
- libffi=3.4.4
- libglib=2.84.2
- libiconv=1.16
- libjpeg-turbo=2.0.0
- libpng=1.6.39
- libtiff=4.7.0
- libwebp-base=1.3.2
- libxml2=2.13.8
- llvm-openmp=17.0.6
- lz4-c=1.9.4
- markupsafe=3.0.2
- mkl=2023.1.0
- mkl-service=2.4.0
- mkl_fft=1.3.8
- mkl_random=1.2.4
- mpc=1.3.1
- mpfr=4.2.1
- mpmath=1.3.0
- ncurses=6.5
- networkx=3.4.2
- numpy=1.24.3
- numpy-base=1.24.3
- openjpeg=2.5.2
- openssl=3.0.17
- pcre2=10.42
- pillow=11.3.0
- pip=25.1
- pixman=0.40.0
- pycparser=2.21
- pysocks=1.7.1
- python=3.10.18
- pytorch=2.2.2
- pytorch-mutex=1.0
- pyyaml=6.0.2
- readline=8.3
- requests=2.32.4
- setuptools=78.1.1
- sqlite=3.50.2
- sympy=1.13.3
- tbb=2021.8.0
- tk=8.6.14
- torchaudio=2.2.2
- torchvision=0.17.2
- typing_extensions=4.12.2
- tzdata=2025b
- urllib3=2.5.0
- wheel=0.45.1
- xz=5.6.4
- yaml=0.2.5
- zlib=1.2.13
- zstd=1.5.6
- pip:
- accelerate==1.9.0
- fsspec==2025.7.0
- hf-xet==1.1.7
- huggingface-hub==0.34.3
- packaging==25.0
- psutil==7.0.0
- regex==2025.7.34
- safetensors==0.6.1
- tokenizers==0.21.4
- tqdm==4.67.1
- transformers==4.55.0
prefix: /opt/miniconda3/envs/qwen3-instruct
requirements.txt
accelerate==1.9.0
brotlicffi @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_05qpoetyrv/croot/brotlicffi_1736182869800/work
certifi @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_fckkf4c22q/croot/certifi_1752653720654/work/certifi
cffi @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_51d1gdg4kr/croot/cffi_1736183297412/work
charset-normalizer @ file:///croot/charset-normalizer_1721748349566/work
filelock @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_90zocybn3d/croot/filelock_1744281394121/work
fsspec==2025.7.0
gmpy2 @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_a9jzez1qcu/croot/gmpy2_1738085473561/work
hf-xet==1.1.7
huggingface-hub==0.34.3
idna @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_2b_jn555_n/croot/idna_1714398852258/work
Jinja2 @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_f4xtf61_ib/croot/jinja2_1741715270435/work
MarkupSafe @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_76vhch455b/croot/markupsafe_1738584048225/work
mkl-fft @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_af8wl3mjfu/croot/mkl_fft_1695058185839/work
mkl-random @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_0fq2s894lk/croot/mkl_random_1695059822529/work
mkl-service==2.4.0
mpmath @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_8fyoqwupl2/croot/mpmath_1690848275746/work
networkx @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_ba1do7fwxc/croot/networkx_1737043398715/work
numpy @ file:///Users/ec2-user/mkl/numpy_and_numpy_base_1682973769567/work
packaging==25.0
pillow @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_59qe1phg3h/croot/pillow_1752524533185/work
psutil==7.0.0
pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work
PySocks @ file:///Users/builder/ci_310/pysocks_1642536366386/work
PyYAML @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_34t43scp15/croot/pyyaml_1728658999838/work
regex==2025.7.34
requests @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_3c5r_7_lxu/croot/requests_1750426340266/work
safetensors==0.6.1
sympy @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_3ej0z2jk7t/croot/sympy_1738108502551/work
tokenizers==0.21.4
torch==2.2.2
torchaudio==2.2.2
torchvision==0.17.2
tqdm==4.67.1
transformers==4.55.0
typing_extensions @ file:///private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_6dn2s8ln8g/croot/typing_extensions_1734714858107/work
urllib3 @ file:///private/var/folders/c_/qfmhj66j0tn016nkx_th4hxm0000gp/T/abs_f8xnjmnanx/croot/urllib3_1750775879857/work
导出命令:
# 一键导出当前 Conda 环境和 pip 包列表,方便读者一键复现
conda activate qwen3-instruct
conda env export --no-builds --name qwen3-instruct > qwen3-instruct-environment.yml
pip freeze > requirements.txt
Comments