
炒作的大数据
从某种意义上说,大数据只是一个空洞的商业术语,就跟所谓的商业智能一样空洞无物。
普通人在提到大数据的时候,可能的感觉是:这玩意很火,哪哪都在提,但具体是干啥的?有什么用?好像也说不上来。

对于投资人和创业者而言,大数据是个热门的融资标签。
对于大多数互联网公司或者工程师而言,大数据实际上只有一个意思,就是把一堆乱七八糟的数据扔到 HDFS 上面然后进行计算、处理、分析、挖掘。
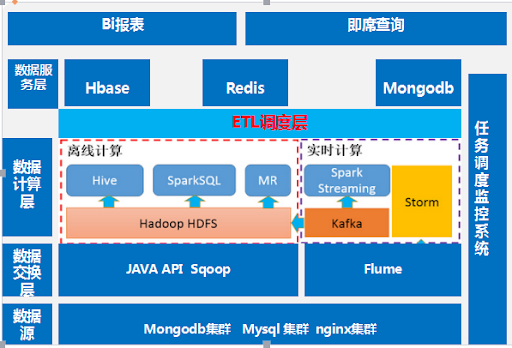
随着技术的演进,之前的一些框架不断的被替换和迭代,例如MR已经被Spark所替代。对于大数据工程师来说,技术迭代是个非常好的事情。因为可以不断的抬高门槛,而且这么多异构的数据,对他们进行存储、计算、分析、挖掘、运维,这需要多个岗位的配合,怎么说建个完善的大数据系统也得几十个人,所以大数据这事解决了很多就业问题。
大数据的由来
Google做搜索,积累了大量的数据,可以根据你的输入,从海量数据从返回你想要的结果,实现毫秒级的响应。它就是通过大数据技术做到的。
在 2003 年, Google 陆续发表了 3 篇论文,首创了大数据这一概念,它们分别是:GFS、MapReduce、BigTable。
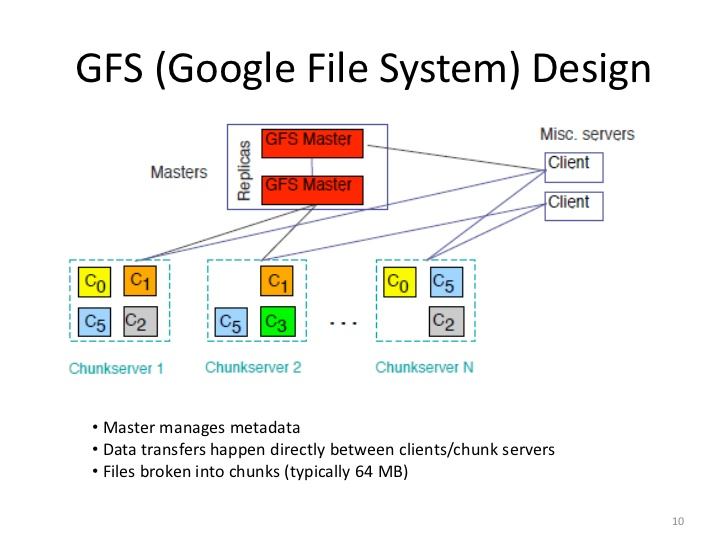

由于单机CPU、内存、硬盘等资源的价格不是随着性能的提升线性提升,而是指数级提升,为了缩减成本,最大化利用资源。Google设计了GFS,来利用普通PC的集群来实现分布式存储非结构化数据,使用Hbase来存储结构化数据,使用MapReduce来实现分布式计算。
数据隐私
做开发的同学都知道,安卓api提供的功能要比苹果丰富的多。那么自然,安卓系统能够获取用户的数据也会更丰富些。
让我用一个思维实验来展示一个 Android 用户在这个大数据生态链中的位置吧(当然任何一个读者都可以亲自尝试,用 iPhone 手机效果会大打折扣)。某个周末,你来到了某个商场,在一个咖啡厅里面点了一杯咖啡,然后开始用智能手机上网。咖啡厅提供了免费 Wi-Fi 网络,由于法规要求需要你提供手机号进行实名认证,你毫不犹豫地输入了手机号。于是免费 Wi-Fi 的服务商知道了你的信息:你的手机号和智能手机的 MAC。然后你开始刷微博,由于微博的 API 通常不使用加密信道,于是 Wi-Fi 热点通过偷窥 HTTP 请求获得了你的微博账号。通过你的微博,Wi-Fi 服务商有可能了解你的性别年龄工作等信息。此外通过该热点请求的很多元信息都会被服务商保留,虽然它们未必知道怎么挖掘这些元信息,但是它们会尽量将你的身份和这些信息关联在一起并长期保留。喝完咖啡,你开始逛街,这时候你的手机会开始扫描热点,商场可以通过 Wi-Fi 探针追踪你的位置。
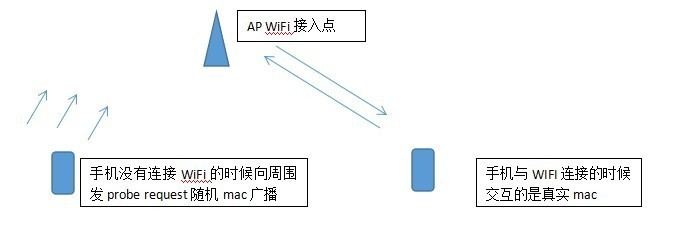
如果商场使用的 Wi-Fi 服务商和咖啡厅是同一家,或者与服务商建立了数据交换的协议,那么商场有可能实名地追踪你的轨迹。商场的 Wi-Fi 服务商同样会非常有耐心地存储你的信息,以备不时之需。在逛街的过程中,你打开了一些购物 App 用于比价,顺便拍了一些照片发给好友。其中一些 App 会把你的 MAC 地址和通过 Wi-Fi 完成的定位信息也发送出去。如果存在一个完备的数据交易网络,任何对你感兴趣的人都有可能获得以下信息:你的电话号码、手机的 MAC、微博账号,何时出现在这个商场,在商场停留了多久,其间使用了哪些 App,在咖啡厅访问了哪些网站。而这一切都离不开 Wi-Fi 和 MAC。如果更极端一点,你使用了专车软件来这个商场,并且你经常来这家商场,那么你很可能已经在商场的常客数据库里了,你的家庭住址也不再是个秘密。
中国的三大寡头都参与了商业 Wi-Fi 的布局。除了微信 Wi-Fi,相信大多数人都没有注意过相关的报道。事实上新闻报道披露的仅仅是冰山一角。
当今时代,我们其实无所遁形,所以要珍爱生命,谨言慎行,多做善事。
大数据与健康
随着基因测序的发展,消费级的全基因组测序成本不断降低,利用大数据和基因技术,将有可能定量的测量和预测有关疾病的患病风险。这也意味着保险公司可以更加精确地估计投保人的健康状况。
大数据具体项目案例(待完善)
出行大数据项目,为什么经纬度信息需要保存在本地,以日志的形式进行收集?
数据是实时上报的,如果网络不好,则可能会造成数据丢失。每3秒上传一次。
flume采集数据,接入到kafka。涉及到flume的拦截器。
offset记录数据消费到哪里了?下次进来继续消费。
从MySQL的binlog中读取数据,Maxwell提取到kafka,spark streaming处理
Maxwell的好处是可以减少业务的压力,以IO换MySQL的压力。

hive -> clickhouse
参考:
Comments